La inteligencia artificial (IA) ha revolucionado la forma en que se abordan los problemas de clasificación y predicción en diversos campos, incluida la medicina. Una de las técnicas más utilizadas en IA es la construcción de árboles de decisión, que son modelos predictivos formados por reglas binarias que permiten repartir las observaciones en función de sus atributos y predecir el valor de una variable respuesta.

¿Qué son los árboles de decisión?
Los árboles de decisión son modelos predictivos que se utilizan para resolver problemas de clasificación y regresión. Estos modelos se construyen a partir de reglas binarias (si/no) que dividen las observaciones en función de sus atributos. Cada nodo del árbol representa una pregunta sobre un atributo y cada rama representa una posible respuesta a esa pregunta. Al llegar a una hoja del árbol, se obtiene una predicción sobre el valor de la variable respuesta.
Una de las ventajas de los árboles de decisión es que son fáciles de interpretar, incluso cuando las relaciones entre los atributos son complejas. Además, pueden manejar tanto atributos numéricos como categóricos, lo que los hace muy versátiles. Otro punto a favor es que no se ven muy influenciados por valores atípicos en los datos. También son muy útiles en la exploración de datos, ya que permiten identificar rápidamente las variables más importantes en un problema. Por último, se pueden aplicar tanto a problemas de clasificación como de regresión.
Por otro lado, los árboles de decisión tienen algunas desventajas. Uno de los principales problemas es su tendencia al overfitting, es decir, a ajustarse demasiado a los datos de entrenamiento y no generalizar bien a nuevos datos. Sin embargo, existen técnicas más complejas, como el bagging, random forest y boosting, que permiten mejorar este problema. También son sensibles a datos de entrenamiento desbalanceados, es decir, cuando una clase domina sobre las demás. Por último, no son capaces de extrapolar fuera del rango de los atributos observados en los datos de entrenamiento.
Implementación de árboles de decisión en Python
En Python, se puede implementar árboles de decisión utilizando la biblioteca scikit-learn (sklearn). Esta biblioteca proporciona las clases DecisionTreeClassifier y DecisionTreeRegressor para problemas de clasificación y regresión, respectivamente.
A continuación, se muestra un ejemplo de cómo clasificar el conjunto de datos Iris utilizando un árbol de decisión en Python:
 ```pythonfrom sklearn.datasets import load_irisimport pandas as pdiris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['target'] = iris['target']# Dividir el conjunto de datos en entrenamiento y pruebafrom sklearn.model_selection import train_test_splitX, y = df.values[:, 0:4], df.values[:, 4]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0, stratify=y)# Crear y entrenar el árbol de decisiónfrom sklearn.tree import DecisionTreeClassifierclf = DecisionTreeClassifier(criterion= entropy, random_state=0)clf.fit(X_train, y_train)# Realizar prediccionesy_pred = clf.predict(X_test)# Calcular la exactitud del modelofrom sklearn.metrics import accuracy_scoreaccuracy = accuracy_score(y_true=y_test, y_pred=y_pred)print('Exactitud: %.3f' % accuracy)```En este ejemplo, se utiliza el conjunto de datos Iris, que es un conjunto de datos muy conocido en el campo de la clasificación. Se divide el conjunto de datos en entrenamiento y prueba utilizando la función train_test_split de scikit-learn. Luego, se crea un objeto DecisionTreeClassifier con el criterio de entropía y se entrena con los datos de entrenamiento. Finalmente, se realizan predicciones sobre los datos de prueba y se calcula la exactitud del modelo.
```pythonfrom sklearn.datasets import load_irisimport pandas as pdiris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)df['target'] = iris['target']# Dividir el conjunto de datos en entrenamiento y pruebafrom sklearn.model_selection import train_test_splitX, y = df.values[:, 0:4], df.values[:, 4]X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0, stratify=y)# Crear y entrenar el árbol de decisiónfrom sklearn.tree import DecisionTreeClassifierclf = DecisionTreeClassifier(criterion= entropy, random_state=0)clf.fit(X_train, y_train)# Realizar prediccionesy_pred = clf.predict(X_test)# Calcular la exactitud del modelofrom sklearn.metrics import accuracy_scoreaccuracy = accuracy_score(y_true=y_test, y_pred=y_pred)print('Exactitud: %.3f' % accuracy)```En este ejemplo, se utiliza el conjunto de datos Iris, que es un conjunto de datos muy conocido en el campo de la clasificación. Se divide el conjunto de datos en entrenamiento y prueba utilizando la función train_test_split de scikit-learn. Luego, se crea un objeto DecisionTreeClassifier con el criterio de entropía y se entrena con los datos de entrenamiento. Finalmente, se realizan predicciones sobre los datos de prueba y se calcula la exactitud del modelo.
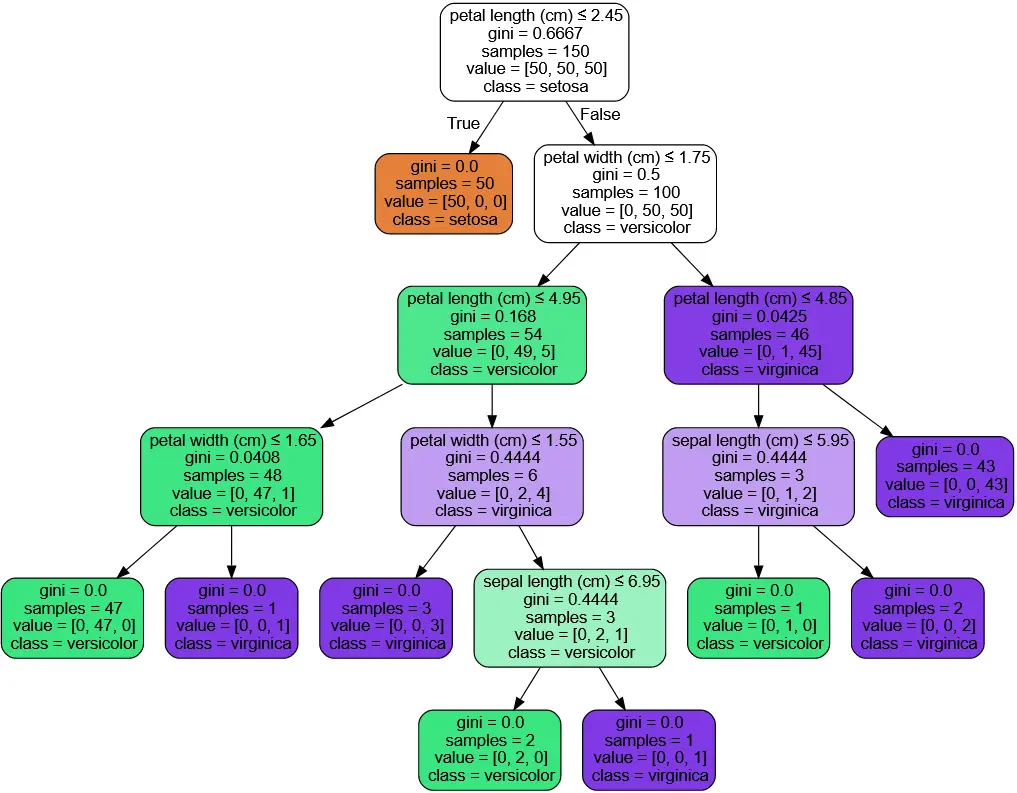
Visualización del árbol de decisión
Una de las ventajas de los árboles de decisión es su capacidad para ser interpretados visualmente. En Python, se puede visualizar un árbol de decisión utilizando la biblioteca PyDotPlus, que permite generar gráficos en formato DOT. A continuación, se muestra un ejemplo de cómo visualizar un árbol de decisión entrenado:
 ```pythonfrom sklearn.tree import export_graphvizfrom pydotplus import graph_from_dot_datafrom IPython import displaydot_data = export_graphviz(clf, feature_names=iris.feature_names)graph = graph_from_dot_data(dot_data)graph.write_png('./images/tree_iris.png')display.Image( ./images/tree_iris.png, width= 700 )```En este ejemplo, se utiliza la función export_graphviz de scikit-learn para generar un archivo DOT que representa el árbol de decisión entrenado. Luego, se utiliza la función graph_from_dot_data de PyDotPlus para convertir el archivo DOT en un gráfico. Finalmente, se guarda el gráfico en formato PNG y se muestra en el notebook.
```pythonfrom sklearn.tree import export_graphvizfrom pydotplus import graph_from_dot_datafrom IPython import displaydot_data = export_graphviz(clf, feature_names=iris.feature_names)graph = graph_from_dot_data(dot_data)graph.write_png('./images/tree_iris.png')display.Image( ./images/tree_iris.png, width= 700 )```En este ejemplo, se utiliza la función export_graphviz de scikit-learn para generar un archivo DOT que representa el árbol de decisión entrenado. Luego, se utiliza la función graph_from_dot_data de PyDotPlus para convertir el archivo DOT en un gráfico. Finalmente, se guarda el gráfico en formato PNG y se muestra en el notebook.
Los árboles de decisión son una herramienta poderosa en el campo de la inteligencia artificial y la ciencia de datos. Permiten resolver problemas de clasificación y regresión de manera intuitiva y fácilmente interpretable. Además, son versátiles y pueden manejar tanto atributos numéricos como categóricos. Sin embargo, tener en cuenta sus limitaciones, como la tendencia al overfitting y la sensibilidad a datos desbalanceados.
En este artículo, hemos visto cómo implementar y visualizar árboles de decisión utilizando Python y la biblioteca scikit-learn. Esperamos que esta información te sea útil para aplicar esta técnica en tus propios proyectos y explorar el maravilloso entorno de la inteligencia artificial.
Si quieres conocer otras notas parecidas a Árboles de decisión en ia: predicción cáncer de mama con python puedes visitar la categoría Inteligencia artificial.